'바닥부터 배우는 강화 학습' 3장에는 밸류를 구할 수 있는 벨만 방정식과 벨만 최적 방정식에 대해서 설명하고 있습니다. 아래 내용은 공부하면서 핵심 내용을 정리한 것입니다.
참고자료
- 도서: 바닥부터 배우는 강화 학습 / 3장 벨만 방정식
- 동영상: https://www.youtube.com/watch?v=NMesGSXr8H4 (후반부)
벨만 방정식
- 밸류를 계산할 때 벨만 방정식을 이용해서 구함
- 벨만 방정식은 시점 $t$에서의 밸류와 시점 $t+1$에서의 밸류 사이의 관계를 다루며 또 가치 함수와 정책 함수 사이의 관계도 다룸
재귀 함수
- 벨만 방정식은 기본적으로 재귀적 관계에 대한 식
- 재귀 함수는 자기 자신을 호출하는 함수
- 피보나치수열(0, 1, 1, 2, 3, 5, 8, 13, 21, ...)의 재귀적인 표현
$$fib(n) = fid(n-1) + fib(n-2)$$
3.1 벨만 기대 방정식
0단계
- 현재 밸류와 다음 상태의 밸류 사이의 관계: $v_{\pi}(s_t) = \mathbb{E}_{\pi}[r_{t+1} + \gamma v_{\pi}(s_{t+1})]$
- 증명
$$\begin{equation}
\begin{split}
v_{\pi}(s_t) &= \mathbb{E}[G_t] \\
&= \mathbb{E}[r_{t+1} + \gamma r_{t+2} + \gamma^2 r_{t+3} + ...] \\
&= \mathbb{E}[r_{t+1} + \gamma (r_{t+2} + \gamma r_{t+3} + ...)] \\
&= \mathbb{E}[r_{t+1} + \gamma G_{t+1}] \\
&= \mathbb{E}[r_{t+1} + \gamma v_{\pi}(s_{t+1})]
\end{split}
\end{equation}$$
- 현재 상태 $s_t$의 밸류인 리턴의 기댓값을 다음 스텝의 보상과 미래에 받을 보상을 더하는 방식으로 계산
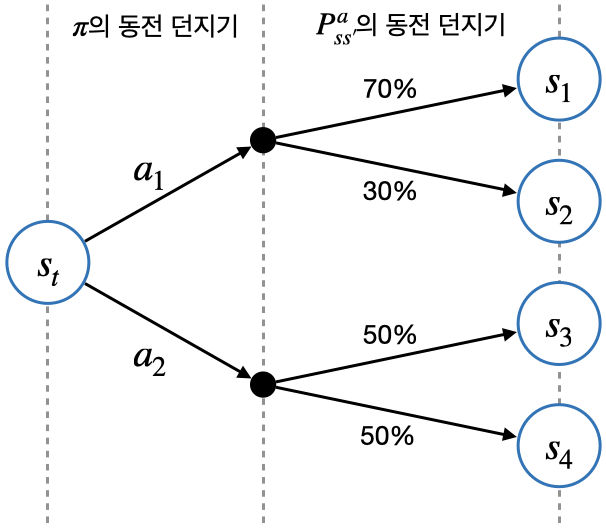
- 위 그림은 동전 던지기를 결정하는 과정
◦ 첫 번째는 정책 $\pi$가 액션 $a_1$ 또는 $a_2$를 선택
예) $\pi(a_1|s_t) = 0.6, \;\;\;\; \pi(a_2|s_t) = 0.4$
◦ 두 번째는 환경에 선택된 액션에 대해서 전이 확률 $P_{ss'}^a$에 따라서 다음 상태 결정
예) $P_{s_ts_1}^{a_1} = 0.7, P_{s_ts_2}^{a_1} = 0.3, P_{s_ts_3}^{a_2} = 0.5, P_{s_ts_4}^{a_2} = 0.5$
1단계
1. $q_{\pi}$를 이용해 $v_{\pi}$ 계산하기

- 위 식에 대한 설명은 아래 그림과 식을 통해 이해 가능
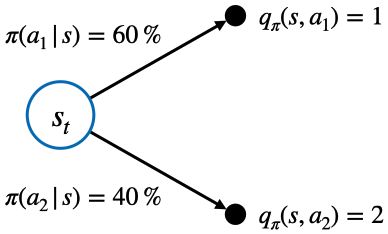
- 액션 밸류 $q_{\pi}(s, a_1)$와 $q_{\pi}(s, a_2)$를 알고 있다고 가정하면 정책 $\pi$를 이용해 상태 $s$의 밸류 계산 가능
$$\begin{equation}
\begin{split}
v_{\pi}(s) & = \pi(a_1|s) * q_{\pi}(s, a_1) + \pi(a_2|s) * q_{\pi}(s, a_2) \\
& = 0.6 * 1 + 0.4 * 2 \\
& = 1.4
\end{split}
\end{equation}$$
- 어떤 상태에서 선택할 수 있는 모든 액션의 밸류를 모두 알고 있다면 해당 상태의 밸류 계산 가능
$$v_{\pi}(s)=\sum_{a \in A} \pi(a|s) q_{\pi}(s, a)$$
2. $v_{\pi}$를 이용해 $q_{\pi}$ 계산하기
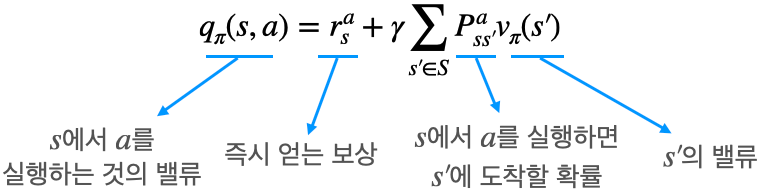
- 위 식에 대한 설명은 아래 그림과 식을 통해 이해 가능
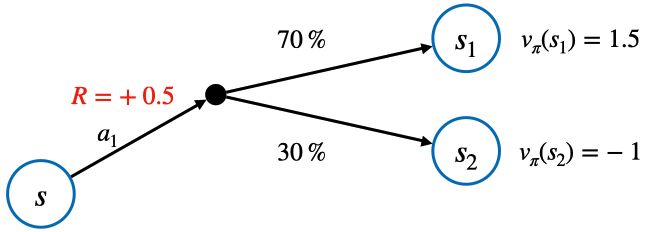
- 액션 $a_1$에 대한 보상 $r_s^{a_1}$, 상태 전이 확률 $P_{ss'}^{a_1}$, 생태 밸류 $v(s_1)$과 $v(s_2)$를 알고 있다고 가정하면 상태 $s$에서 액션 $a_1$의 밸류 계산 가능
$$\begin{equation}
\begin{split}
q_{\pi}(s, a_1) & = r_s^{a_1} + P_{ss_1}^{a_1} * v_{\pi}(s_1) + P_{ss_2}^{a_1} * v_{\pi}(s_2) \\
& = 0.5 + 0.7 * 1.5 + 0.3 * (-1) \\
& = 1.25
\end{split}
\end{equation}$$
- 위 식을 시그마를 이용해 일반화 한 식
$$q_{\pi}(s,a) = r_s^a + \gamma \sum_{s' \in S} P_{ss'}^a v_{\pi}(s')$$
2단계
- 1단계 $q_{\pi}$에 대한 식을 $v_{\pi}$에 대한 식에 대입하면 아래와 같음
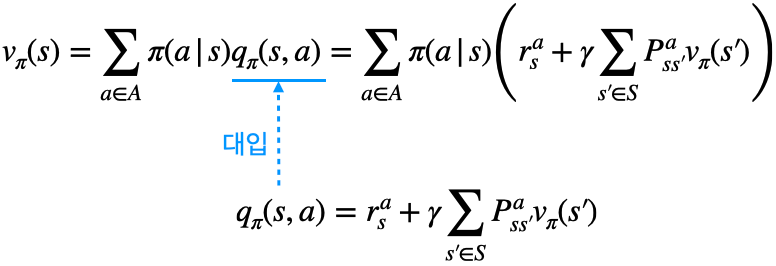
- 반대로 $v_{\pi}$에 대한 식을 $q_{\pi}$에 대한 식에 대입하면 아래와 같음

- $v_{\pi}(s)$에 대한 벨만 기대 방정식
◦ 0단계: $v_{\pi}(s)=\mathbb{E}_{\pi}[r' + \gamma v_{\pi}(s')]$
◦ 2단계: $v_{\pi}(s)=\sum_{a \in A} \pi(a|s) \left( r_s^a + \gamma \sum_{s' \in S}P_{ss'}^a v_{\pi}(s') \right)$ - 2단계 식을 계산하기 위해서 다음 2가지를 반드시 알아야 함
◦ 보상 함수: $r_s^a$
◦ 전이 확률: $P_{ss'}^a$ - 실제로는 대부분의 경우 MDP를 모르기 때문에 경험(experience)을 통해 학습
◦ 모델 프리(model-free): MDP를 모를 때 학습하는 접근법
◦ 모델 베이스(model-based): MDP를 알고 있을 때 학습하는 접근법
3.2 벨만 최적 방정식
◈ 최적 밸류와 최적 정책
- 최적 밸류의 정의는 다음과 같음
$$\begin{equation}
\begin{split}
v_{*}(s) &= \underset{\pi}{\mathrm{max}} \; v_{\pi}(s) \\
q_{*}(s, a) &= \underset{\pi}{\mathrm{max}} \; q_{\pi}(s, a)
\end{split}
\end{equation}$$
- 모든 상태에서 최적 밸류를 갖게 하는 정책 $\pi$가 최소한 1개 이상 존재
- 최적 정채 (optimal policy)의 정의
◦ 최적의 정책 $\pi_{*}$를 따를 때 얻는 보상의 총합이 가장 크다
◦ 모든 상태 $s$에 대해, $v_{\pi_1}(s) > v_{\pi_2}(s)$ 이면 $\pi_1 > \pi_2$
◦ MDP 내의 모든 $\pi$에 대해 $\pi_{*} > \pi$를 만족하는 $\pi_{*}$가 반드시 존재 - 최적 정책, 최적 밸류, 최적 액션 밸류의 관계
◦ 최적의 정책: $\pi_{*}$
◦ 최적의 밸류: $v_{*}(s) = v_{\pi_{*}}(s)$ ($\pi_{*}$를 따랐을 때의 밸류)
◦ 최적의 액션 밸류: $q_{*}(s, a) = q_{\pi_{*}}(s, a)$ ($\pi_{*}$를 따랐을 때의 액션 밸류)
◈ 벨만 최적 방정식
- 액션을 선택할 때 확률적으로 선택하는 것이 아니라 최댓값(max) 연산자를 통해 제일 좋은 액션을 선택
0단계
$$\begin{equation}
\begin{split}
v_{*}(s) &= \underset{a}{\mathrm{max}} \; \mathbb{E}[r + \gamma v_{*}(s') | s_t = s, a_t = a] \\
q_{*}(s, a) &= \mathbb{E}[r + \gamma \underset{a'}{\mathrm{max}} \; q_{*}(s', a')| s_t = s, a_t = a]
\end{split}
\end{equation}$$
- 액션은 확률을 따르지 않고 $\mathbb{E}[r+\gamma v_{*}(s')]$을 최대로 하는 액션을 선택
- 환경에 의한 전이 확률 $P_{ss'}^a$에 의해 다양한 $s'$에 도달할 수 있기 때문에 기댓값 연산자가 필요
1단계
1. $q_{*}$를 이용해 $v_{*}$ 계산하기
$$v_{*}(s) = \underset{a}{\mathrm{max}} \; q_{*}(s, a)$$
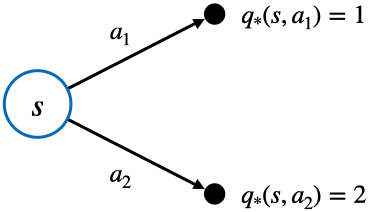
- 위 그림에서 최적 액션은 두 개의 액션 중 가치가 높은 $a_2$를 선택하는 것
- 수식으로 표현하면 아래와 같음
$$\begin{equation}
\begin{split}
v_{*}(s) &= \underset{a}{\mathrm{max}} \; q_{*}(s, a) \\
&= \mathrm{max}(q_{*}(s, a_1), q_{*}(s, a_2)) \\
&= \mathrm{max}(1, 2) = 2
\end{split}
\end{equation}$$
2. $v_{*}$를 이용해 $q_{*}$ 계산하기
$$q_{*}(s, a)=r_s^a + \gamma \sum_{s' \in S} P_{ss'}^av_{*}(s')$$
2단계
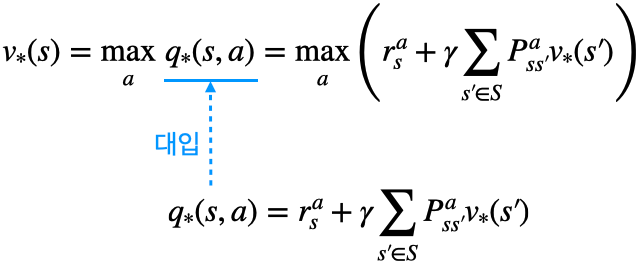
- 위 수식과 같이 $v_{*}(s)$의 식에 $q_{*}(s, a)$의 식을 대입
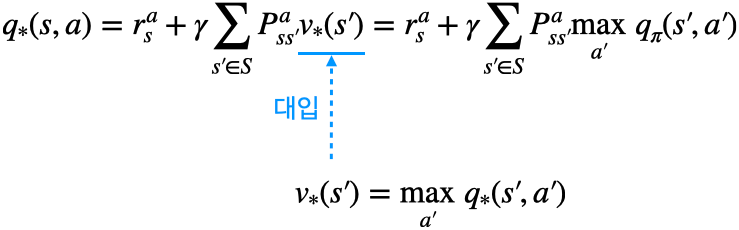
- 위 수식과 같이 $q_{*}(s, a)$의 식에 $v_{*}(s)$의 식을 대입
'강화 학습 > 바닥부터 배우는 강화 학습' 카테고리의 다른 글
| 바닥부터 배우는 강화 학습 | 06. MDP를 모를 때 최고의 정책 찾기 (0) | 2023.01.05 |
|---|---|
| 바닥부터 배우는 강화 학습 | 05. MDP를 모를 때 밸류 평가하기 (0) | 2022.11.29 |
| 바닥부터 배우는 강화 학습 | 04. MDP를 알 때의 플래닝 (0) | 2022.11.14 |
| 바닥부터 배우는 강화 학습 | 02. 마르코프 결정 프로세스 (0) | 2022.11.04 |
| 바닥부터 배우는 강화 학습 | 01. 강화 학습이란 (2) | 2022.11.04 |