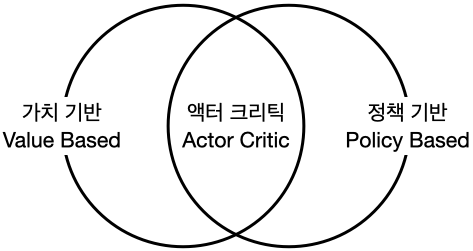
'바닥부터 배우는 강화 학습' 8장에는 가치 기반 에이전트를 학습하는 방법에 대해서 설명하고 있습니다. 아래 내용은 공부하면서 핵심 내용을 정리한 것입니다. 참고자료 도서: 바닥부터 배우는 강화 학습 / 8장 가치 기반 에이전트 이번 챕터에서 다룰 문제 ◦ 모델 프리 ◦ 상태 공간 (state space)과 액션 공간(action space)이 매우 커서 테이블에 담지 못할 상황 강화 학습에 뉴럴넷을 접목시키는 접근법 2가지 ◦ 함수 vπ(s)vπ(s)나 qπ(s)qπ(s)를 뉴럴넷으로 표현하는 방식 ◦ 정책 함수 π(a|s)π(a|s)를 뉴럴넷으로 표현하는 방식 가치 기반(value-based): 가치 함수에 근거하여 액션을 선택 모델-프리 상황에서는 v(s)v(s)만 가지고 액션을 정할 수 없기 때문..