강화 학습 공부를 다시 시작합니다. 예전에 관심 있게 봤던 팡요랩의 저가가 쓰신 '바닥부터 배우는 강화 학습'을 첫 번째 공부 교재로 사용하려고 합니다. 아래 내용은 공부하면서 핵심 내용을 정리한 것입니다.
참고자료
- 도서: 바닥부터 배우는 강화 학습 / 1장 강화 학습이란
- 동영상: https://www.youtube.com/watch?v=NMesGSXr8H4
1.1 지도 학습과 강화 학습
◈ 기계 학습의 분류
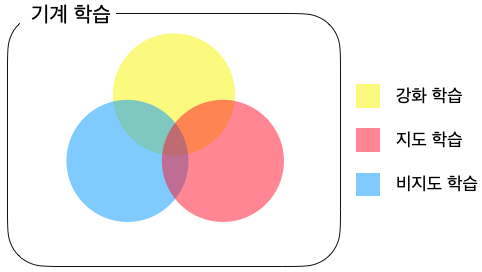
- 기계학습 (machine learning)
◦ 강화 학습(reinforcement learning):
지도자의 도움 없이 혼자서 수많은 시행착오(Trial and Error)를 거치면서 학습하는 방법
◦ 지도 학습(supervised learning):
아버지가 아들에게 자전거 타는 방법을 가르쳐 주듯이 지도자(Supervisor)의 도움을 받아서 학습(Learning) 하는 방법
◦ 비지도 학습(unsupervised learning):
예 1) 사람 얼굴 1만 장을 학습 후에 새로운 사람 얼굴을 생성하는 인공지능
예 2) 주어진 데이터의 성질이 비슷한 것들끼리 묶는 클러스터링
◈ 지도 학습
- 학습 데이터(training data):
예) 남자, 여사 성별이 구분된 사진 1만 장 - 학습 데이터를 기반으로 학습한 후 인물 사진이 주어지면 성별을 구별하는 모델을 학습하는 것이 지도 학습
- 테스트 데이터(test data):
정답을 모르지만 궁극적으로 정답을 맞히고자 하는 데이터
◈ 강화 학습
- "순차적 의사결정 문제에서 누적 보상을 최대화하기 위해 시행착오를 통해 행동을 교정하는 학습 과정"
1.2 순차적 의사결정 문제
강화 학습이 풀고자 하는 문제는 순차적 의사결정(sequential decision making) 문제
◈ 샤워하는 남자
- 샤워할 때의 아래 4가지 행동을 순서에 맞게 해야 한다. 만일 순서가 바뀐다면 다른 문제가 발생할 수 있다.
1) 옷을 벗는다.
2) 샤워를 한다.
3) 물기를 닦는다.
4) 옷을 입는다. - 어떤 상황에서 현재의 행동의 다음 상황에 영향을 주며, 결국 연이은 행동을 잘 선택해야 하는 문제가 바로 순차적 의사결정 문제
◈ 순차적 의사결정 문제의 예시
주식 투자에서의 포트폴리오 관리
- 언제 어떤 주식을 사고 팔지를 결정해야 하는 주식 포트폴리오 관리는 순차적 의사결정 문제로 볼 수 있음
운전
- 어떤 도로를 이용할지, 어떤 차선을 이용할지, 브레이크 또는 액셀을 밟을지를 결정하는 것도 순차적 의사결정 과정
게임
- 대부분의 게임이 잘게 쪼개진 선택의 연속으로 이루어져 있으며, 주어지 상황 안에서 최선의 선택을 내려야 함
1.3 보상
보상(reward)이란 얼마나 잘하고 있는지 알려주는 신호.
강화 학습의 목적은 과정에서 받는 보상의 총합, 즉 누적 보상(cululative reward)을 최대화하는 것
어떻게 X 얼마나 O
- "어떻게"에 대한 정보를 담고 있지 않음.
- "얼마나" 잘하고 있는지를 평가.
- 수많은 시행착오를 통해서 "어떻게"를 학습하고 그 결과로 "얼마나"에 해당하는 보상을 최대화
스칼라
- 보상은 스칼라(scalar) 값
◦ 예) 자산 포트폴리오 배분에서의 이득
◦ 예) 자전거 타기에서 넘어지지 않고 나아간 거리
◦ 예) 게임에서의 승리
희소하고 지연된 보상
- 희소(sparse): 보상은 매번 행동을 선택할 때마다 주어지지 않고 훨씬 가끔 주어질 수 있음
- 지연(delay): 보상은 행동을 한 후 한참 후에 주어질 수 있음 (예: 바둑은 경기가 끝날 때까지 승리·패배 보상을 결정할 수 없음)
1.4 에이전트와 환경
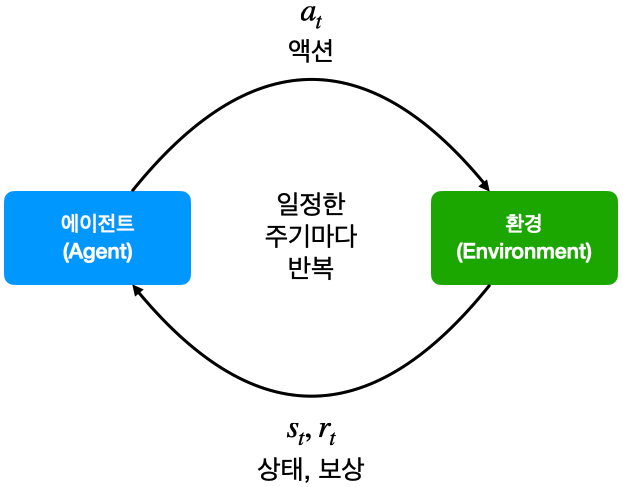
에이전트가 액션(action)을 하고 그에 따라 상황이 변하는 하나의 루프(loop)라 했을 때 이 루프가 끊임없이 반복되는 것을 순차적 의사결정 문제라 할 수 있음.
- 에이전트는 강화 학습의 주인공이자 주체
◦ 현재 상황 $s_t$에서 어떤 액션을 해야 할지 $a_t$를 결정
◦ 결정된 행동 $a_t$를 환경으로 보냄
◦ 환경으로부터 그에 따른 보상과 다음 상태의 정보를 받음 - 에이전트를 제외한 모든 요소가 환경
- 현재 상태에 대한 모든 정보를 숫자로 기록해 놓은 것이 상태(state)
- 환경은 결국 상태 변화(state transition)를 일으키는 역할을 담당
◦ 에이전트로부터 받은 액션 $a_t$를 통해서 상태 변화를 일으킴
◦ 그 결과 상태는 $s_t \to s_{t+1}$로 바뀜
◦ 에이전트에게 줄 보상 $r_{t+1}$도 함께 계산
◦ $s_{t+1}$과 $r_{t+1}$을 에이전트에게 전달
1.5 강화 학습의 위력
◈ 병렬성의 힘
수많은 컴퓨터를 병렬로 연결해서 시뮬레이션을 진행하고 시뮬레이션 결과를 모아서 중앙에서 학습하면 빠른 학습 가능
◈ 자가 학습 (self-learning)의 매력
시뮬레이션 환경 속에 던져 놓고 목적만 알려주고 알아서 배우게 하는 강화 학습이 유연하고 자유롭고 성능면에서도 뛰어남
'강화 학습 > 바닥부터 배우는 강화 학습' 카테고리의 다른 글
| 바닥부터 배우는 강화 학습 | 06. MDP를 모를 때 최고의 정책 찾기 (0) | 2023.01.05 |
|---|---|
| 바닥부터 배우는 강화 학습 | 05. MDP를 모를 때 밸류 평가하기 (0) | 2022.11.29 |
| 바닥부터 배우는 강화 학습 | 04. MDP를 알 때의 플래닝 (0) | 2022.11.14 |
| 바닥부터 배우는 강화 학습 | 03. 벨만 방정식 (0) | 2022.11.04 |
| 바닥부터 배우는 강화 학습 | 02. 마르코프 결정 프로세스 (0) | 2022.11.04 |