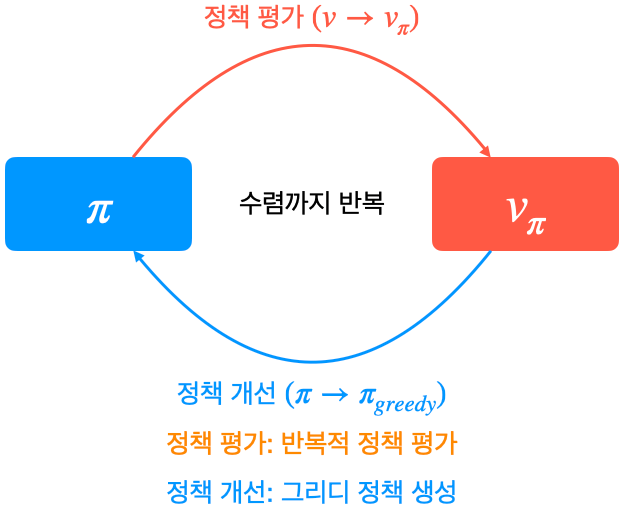
'바닥부터 배우는 강화 학습' 6장에는 MDP를 모르고 있는 경우 최고의 정책을 찾는 방법에 대해서 설명하고 있습니다. 아래 내용은 공부하면서 핵심 내용을 정리한 것입니다. 참고자료 도서: 바닥부터 배우는 강화 학습 / 6장 MDP를 모를 때 최고의 정책 찾기 동영상: https://www.youtube.com/watch?v=2h-FD3e1YgQ&list=PLpRS2w0xWHTcTZyyX8LMmtbcMXpd3s4TU&index=5 6.1 몬테카를로 컨트롤 ◈ 정책 이터레이션을 그대로 사용할 수 없는 이유 첫 번째: 반복적인 정책평가를 사용할 수 없음 모델 프리 상황에서는 보상함수 ras와 전이확률 Pass′을 모르기 때문에 아래 벨만 기대 방정식을 사용할 수 없음 $$v_{\pi}(s)..